
Как спарсить сайт в excel
Парсер сайтов и файлов (парсинг данных с сайта в Excel)

Надстройка Parser для Excel — простое и удобное решение для парсинга любых сайтов (интернет-магазинов, соцсетей, площадок объявлений) с выводом данных в таблицу Excel (формата XLS* или CSV), а также скачивания файлов.
Особенность программы — очень гибкая настройка постобработки полученных данных (множество текстовых функций, всевозможные фильтры, перекодировки, работа с переменными, разбиение значения на массив и обработка каждого элемента в отдельности, вывод характеристик в отдельные столбцы, автоматический поиск цены товара на странице, поддержка форматов JSON и XML).
В парсере сайтов поддерживается авторизация на сайтах, выбор региона, GET и POST запросы, приём и отправка Cookies и заголовков запроса, получение исходных данных для парсинга с листа Excel, многопоточность (до 200 потоков), распознавание капчи через сервис RuCaptcha.com, работа через браузер (IE), кеширование, рекурсивный поиск страниц на сайте, сохранение загруженных изображений товара под заданными именами в одну или несколько папок, и многое другое.
Поиск нужных данных на страницах сайта выполняется в парсере путем поиска тегов и/или атрибутов тегов (по любому свойству и его значению). Специализированные функции для работы с HTML позволяют разными способами преобразовывать HTML-таблицы в текст (или пары вида название-значение), автоматически находить ссылки пейджера, чистить HTML от лишних данных.
За счёт тесной интеграции с Excel, надстройка Parser может считывать любые данные из файлов Excel, создавать отдельные листы и файлы, динамически формировать столбцы для вывода, а также использовать всю мощь встроенных в Excel возможностей.
Поддерживается также сбор данных из текстовых файлов (формата Word, XML, TXT) из заданной пользователем папки, а также преобразование файлов Excel из одного формата таблицы в другой (обработка и разбиение данных на отдельные столбцы)
В программе «Парсер сайтов» можно настроить обработку нескольких сайтов. Перед запуском парсинга (кнопкой на панели инструментов Excel) можно выбрать ранее настроенный сайт из выпадающего списка.
На видео рассказывается о работе с программой, и показан процесс настройки парсера интернет-магазина:
Дополнительные видеоинструкции, а также подробное описание функционала, можно найти в разделе Справка по программе
В программе можно настроить несколько парсеров (обработчиков сайтов).
Любой из парсеров настраивается и работает независимо от других.
Настройка программы, — дело не самое простое (для этого, надо хоть немного разбираться в HTML)
Если вам нужен готовый парсер, но вы не хотите разбираться с настройкой,
— закажите настройку парсера разработчику программы. Стоимость настройки под конкретный сайт — от 1500 рублей.
(настройка под заказ выполняется только при условии приобретения лицензии на надстройку «Парсер» (2700 руб)
Программа не привязана к конкретному файлу Excel.
Вы в настройках задаёте столбец с исходными данными (ссылками или артикулами),
настраиваете формирование ссылок и подстановку данных с сайта в нужные столбцы,
нажимаете кнопку, — и ваша таблица заполняется данными с сайта.
Программа «Парсер сайтов» может быть полезна для формирования каталога товаров интернет-магазинов,
поиска и загрузки фотографий товара по артикулам (если для получения ссылки на фото, необходимо анализировать страницу товара),
загрузки актуальных данных (цен и наличия) с сайтов поставщиков, и т.д. и т.п.
Можно попробовать разобраться с работой программы на примерах настроенных парсеров
Как скачать и протестировать программу
Для загрузки надстройки Parser воспользуйтесь кнопкой Скачать программу
Если не удаётся скачать надстройку, читайте инструкцию про антивирус
Если скачали файл, но он не запускается, читайте почему не появляется панель инструментов
Это полнофункциональная пробная (TRIAL) версия, у вас есть 10 дней бесплатного использования ,
в течение которых вы можете протестировать работу программы.
Этого вполне достаточно, чтобы всё настроить и проверить, используя раздел Справка по программе
Если вам понравится, как работает программа, вы можете Купить лицензию
Лицензия (для постоянного использования) стоит 2700 рублей .
В эту стоимость входит активация на 2 компьютера (вы сможете пользоваться программой и на работе, и дома).
Если нужны будут дополнительные активации, их можно будет в любой момент приобрести по 600 рублей за каждый дополнительный компьютер.
- 521086 просмотров
Комментарии
Здравствуйте, Дмитрий
Напишите мне в скайп, решим проблему.
В последнее время на одном из компьютеров стало очень долго открываться окно настроек Парсера. Также очень много времени требуется для сохранения даже самых незначительных изменений. Также сам процесс парсинга данных занимает в разы больше времени, чем это было до возникновения данной проблемы. На другой машине таких проблем не возникает.
Прошу подсказать, с чем могут быть связаны такие подтормаживания надстройки? Сам Excel, ровно как и Windows, не тормозят ни капли. Машина мощная. Судя по графикам, процессор грузится в моменты открытия и внесения изменений в настройки приблизительно на 30%.
Очень надеюсь на Ваш совет, т.к. подобное поведение надстройки вызывает существенные трудности при её эксплуатации.
Теоретически возможно, конечно, но я версию под Mac делать не буду.
Мои программы работают только под Windows
Здравствуйте. А можно ли сделать такой парсер для MS EXEl под mac и если да, сколько это будет стоить?
Если сделаете пример результата в Экселе, то можно
Добрый день! Есть ли возможность парсинга части таблицы из word в excel с сохранением разметки?
В действии «Поиск тегов» первым параметром указываете div, а четвертым data-brand
Здравствуйте, как из такого div взять data-brand?
div class=»col-sm-3 col-xs-6 brand» style=»text-align: center; padding-bottom: 15px;» data-brand=»110″
Если это ваш сайт, то вы и без парсера можете выгрузить эти данные из админки.
Если это не ваш сайт, то эти данные получить невозможно.
Привет. Нужны дааные которые пользователи вводят при регистрации на сайте в специальной форме, это можно сделать с помощью вашей программы или надо заказывать настройку такого парсинга отдельно?
Антон, парсер может обработать и такие ссылки, просто настройка немного другая
(так как в парсере не работает javascript, надо смотреть, какие запросы выполняет браузер, и делать аналогично)
Можем настроить под заказ.
Приветствую. На многих сайтах ссылки (особенно паджинатора) прописаны яваскриптом. Имею в виду конструкции вида | href=»#» | Пробовал разные настройки, парсер их не видит. Я что-то упускаю или парсер рассчитан исключительно на plain html?
Сделать можем, если вы вышлете задание (с какого сайта и откуда конкретно эти данные брать)
Друзья, часто нужны контакты (телефоны) ИП из разных регионов РФ.
Есть ли у кого-то готовый парсер на такой случай или может ли кто-то сделать его за гонорар?
Можем настроить под заказ.
Заказы на парсер принимаются в таком виде
https://excelvba.ru/programmes/Parser/order
Добрый день,я просто пока не могу понять, что для этого нужно выбрать, как сделать значение в отдельном столбце понятно, но тогда будет сильно растянутая таблица, а вот что каждое значение в отдельной строке (как новое) не понятно(((((
Татьяна, да, конечно можно.
Добрый день, подскажите можно ли в отдельные строки выводить товаров с таблицы товара (одно наименование, разные характеристики-модели). Вот страница для примера https://www.sss.by/prod/mebel-dlya-vannoi-komnaty/umby-pod-umyvalnik/umb.
В действии «Получить все ссылки пейджера» в параметре «Дополнительные параметры» напишите step=1
пейджер отображает только четные страницы http://opt.ros-decor.ru/category/photoshtori/tsvety/
не могу разобраться, помогите
Игорь, какая примерно цена по настройке парсера?
При парсинге сайта, программа останавливается на 47% и все. Несколько раз пробовал, но все время тормозит, что делать?
Дмитрий, настроено значит что-то не так.
Можем перенастроить под заказ.
Добрый день. Парсер запускается в работу, загружает данные с 4х страниц, а потом выдает ошибку «Не задан URL страницы для загрузки в действии «Загрузить исходный код веб-страницы»». Скриншот http://prntscr.com/pbxcty. Подскажите в чем может быть проблема?
Сергей, Цены и прочие данные по каждому размеру на сайте Аскона получаются пост-запросами.
Сначала получаем все возможные размеры (в коде страницы ищем select id=»product-buy__drop-size», из него берем теги option),
а потом для каждого размера выполняем POST запрос (там около 18 параметров в нём, но меняются только три: размер, ID товара, и еще что-то)
Повозиться немного придется с настройкой, но ничего сложного нет.
Нет, цен в конце страницы нет. Я нашел в видео инструкцию по GET запросам и вроде как разобрался, спасибо! Но через браузер. Попробую следующим этапом перейти на метод загрузки кода.
Здравствуйте, Сергей
Браузер парсеру для этой задачи не нужен.
В большинстве случаев, даже щёлкать ничего не надо, — в коде страницы обычно есть все размеры и цены на них.
Если же нет, то смотрите какой запрос выполняет ваш браузер.
Подробнее об этом во второй видеоинструкции:
https://excelvba.ru/programmes/Parser/manuals/Loading_Pages_and_Logon
Добрый день! Пытаюсь настроить парсинг позиций на этом сайте:
https://www.askona.ru/tekstil/postelnoe-beljo/askona-home-belyy-sneg-pro.
Для получения цены нужно из дропдауна выбрать нужный размер, то есть попросить парсер сделать два клика: на дропдауне и на нужном элементе, и тогда меняется цена. Не могу этого добиться 🙁 «Щелкнуть по элементу в Internet Explorer» не срабатывает так, как я этого хотел бы. Подозреваю, что это настраивается где-то через GET/POST. Использую платную версию программы.
Хочу настроить сам, опыт важен. Скажите, в какую сторону курить? Может, есть образец или запись семинара, где это было бы освещено?
Ярослав, с этими Гугл сервисами, — да, непросто.
Парсер можно попробовать настроить под них (без использования ИЕ), но наверняка там повозиться придется с настройкой (ибо всё на скриптах).
На данный момент, 99.99999% сайтов парсеру вполне доступны, так что какого-то специализированного решения под подобные гугл-сервисы пока не планируется.
Я вообще обычно не настраиваю парсер под Google и Яндекс, — с ними много сложностей (типа капчи и прочих мешающих парсингу вещей), да и для подобных сервисов обычно существуют специализированные решения / парсеры, заточенные под парсинг выдачи поисковых систем.
Мой же парсер — для всех остальных сайтов, кроме этих двух.
IE тихонько умирает. Сервисы типа Гугл тренды или Гугл реклама уже перестали грузиться в IE.
Силами парсера они также не грузятся. Что делать ?
Парсер сайтов
Содержание
- О программе «Парсер сайтов»
- Видеообзор возможностей парсера, работа с программой
- Какие задачи решает программа
- Скачать демо-версию «Парсер сайтов»
- Инструкция по первому запуску программы
- Преимущества работы с программой
О программе «Парсер сайтов»

Программа «Парсер сайтов» разработана для сбора, анализа, выборки, группировки, структуризации, трансформации данных с последующим выводом данных в таблицу Excel в форматах xls* и csv.
Парсер создан на VBA (Visual Basic for Applications) и представлен в виде надстройки для MS Excel, по сути это набор макросов, каждый набор отвечает за выполнение определенных функций при обработке.
Для парсинга любого сайта пишется подпрограмма управления макросами (файл-настройка с расширением .xlp).
Таким образом, для работы программы необходимы: файл надстройки Parser.xla и файл управления надстройкой Name.xlp (Name — имя файла).
Видеообзор парсера
Какие задачи решает программа
- Парсинг товаров для интернет магазинов в таблицу для последующего экспорта данных. Связь по артикулам с прайсами поставщиков. Загрузка фото под нужными именами в папки на жесткий диск.
- Формирование баз контактов организаций: e-mail, телефонов, адресов, наименований.
- Сбор и вывод в таблицу коэффициентов и результатов спортивных событий для дальнейшего анализа. Отслеживание и поиск необходимых матчей по условиям.
- Парсинг файлов и папок на жестком диске, поиск по маске, смена имени, удаление, группировка.
- Загрузка файлов любых форматов из сети интернет на жесткий диск или в облачное хранилище: фотографии, музыка, документы.
- Запуск программы по расписанию: раз в час, неделю и т.д. Возможность зацикливания программы для отслеживания динамических данных на веб-ресурсах. При нужном совпадении данных есть возможность передачи их на e-mail или в Telegram.
- При помощи парсера возможен не только сбор, но и подстановка/передача данных через браузер (например, отправка сообщений, простановка лайков в соцсетях и многое другое).
- Парсинг с прохождением авторизации, передачей cookies и решением различных captcha.
- Многопоточная загрузка, одновременный парсинг нескольких источников.
Скачать демо-версию «Парсер сайтов»
Скачать пробную (TRIAL) версию программы (версия 3.4.13 от 31.03.2019). Пробная версия имеет полный функционал и ограничена 10 дневным тестовым периодом (нажмите на зеленый кубик).
Купить вечную лицензию можно тут
Скачать тестовую настройку программы для сайта relefopt.ru (нажмите на шестерню). Тестовая настройка предполагает частичную загрузку данных для демонстрации возможностей парсера.
Заказать под Ваш источник можно тут
Инструкция по первому запуску программы
Перед работой с программой ознакомьтесь с ответами на технические вопросы о версиях Windows, Excel, как включить макросы и прочее.
Запуск на примере тестовой настройки для парсинга сайта-поставщика https://relefopt.ru/ (для наглядного восприятия посмотрите видео):
- Создаем в любом месте папку на жесткой диске или в облачном хранилище с произвольным названием, например, «Парсер». И скачиваем в неё программу Parser.xla.
- Заходим в папку «Парсер», кликаем правой кнопкой мыши по файлу программы Parser.xla, нажимаем «Свойства», ставим галочку «Разблокировать», жмем «Применить» затем «ОК»:

- Открываем файл двойным кликом левой кнопкой мыши, в папке «Парсер» будет создана папка «Настройки парсеров» и запустится Excel с дополнительными элементами в ленте:
- В папку «Настройки парсеров» скачиваем файл настройки Relefopt.ruTest.xlp, далее в Экселе нажимаем «Дополнительно» и «Обновить панель инструментов»:
- В ленте из выпадающего списка выбираем название «Relefopt.ruTest» и нажимаем «Начать загрузку данных»:
- Ожидаем завершения загрузки данных. Исходя из технического задания на парсинг сайта relefopt.ru в процессе работы программы в папке с парсером созданы папки Downloads (для загрузки фото) и files (для сохранения файлов выгрузки) с подпапками для каждого раздела отдельно.
- Если желаете прервать загрузку нажимаем «Отмена» — «Да»:





Примечание: рассмотренный выше парсер загружает по одной позиции с каждой подкатегории сайта. Другие тестовые настройки можно найти в каталоге работ.
Создать техническое задание на настройку программы «Парсер сайтов» можно тут.
Преимущества работы с программой
- Широко масштабируемый постоянно обновляемый программный комплекс, позволяет решить самые разнообразные задачи.
- Настройка программы практически под любой веб-ресурс для получения необходимой информации с выводом нужных Вам данных в таблицу.
- Запуск парсера пользователем в любое время неограниченное количество раз для получения самой актуальной информации.
- Прямая работа с исполнителем для настройки программы.
- Наш опыт настройки программы более 3 лет, реализовано более 800 проектов.
- Выше перечисленное позволяет получить Вам необходимые данные в сжатые сроки по доступной цене.
Остались вопросы? Пишите, звоните Skype и e-mail, с удовольствием ответим.
Автоматизированный парсинг сайтов

В работе специалистов сферы информационных технологий часто возникает задача собрать какую-либо информацию с сайтов. И она априори не может быть лёгкой.
Поэтому для автоматизированного и упрощённого извлечения и группировки данных был придуман парсинг.
В этом посте я собрала информацию о том, что это, как работает и для чего нужно, а также поделюсь методами и инструментами, с которыми парсинг станет для вас не такой сложной задачей.
1. Что такое парсинг сайтов
Процесс парсинга — это автоматическое извлечение большого массива данных с веб-ресурсов, которое выполняется с помощью специальных скриптов в несколько этапов:
- Построение запроса для получения первоначальной информации.
- Извлечение информации согласно прописанному алгоритму.
- Формирование и структурирование информации.
- Сохранение полученных данных.
Чтоб извлекались только определённые данные, в программе задаётся специальный язык поиска, который описывает шаблоны строк — регулярное выражение. Регулярное выражение основано на использовании набора определённых символов, которые описывают информацию, нужную для поиска. Подробнее о работе с регулярными выражениями вы можете узнать на посвящённом им сайте.
Инструменты для парсинга называются парсерами — это боты, запрограммированные на отсеивание баз данных и извлечение информации.
Чаще всего парсеры настраиваются для:
- распознавания уникального HTML;
- извлечения и преобразования контента;
- хранения очищенных данных;
- извлечения из API.
2. Зачем и когда используют парсинг
Зачастую парсинг используется для таких целей:
- Поиск контактной информации. Парсинг помогает собирать почту, номера телефонов с разных сайтов и соцсетей.
- Проверка текстов на уникальность.
- Отслеживание цен и ассортимент товаров-конкурентов.
- Проведение маркетинговых исследований, например, для мониторинга цен конкурентов для работы с ценообразованием своих товаров.
- Превращение сайтов в API. Это удобно, когда нужно работать с данными сайтов без API и требуется создать его для них.
- Мониторинг информации с целью поддержания её актуальности. Часто используется в областях, где быстро меняется информация (прогноз погоды, курсы валют).
- Копирование материалов с других сайтов и размещение его на своём (часто используется на сайтах-сателлитах).
Выше перечислены самые распространённые примеры использования парсинга. На самом деле их может быть столько, сколько хватит вашей фантазии.
3. Как парсить данные с помощью различных сервисов и инструментов
Способов парсить данные сайтов, к счастью, создано великое множество: платных и бесплатных, сложных и простых.
Предлагаю ознакомиться с представителями разных типов и разобрать, как работает каждый.
Google Spreadsheet
С помощью функций в таблицах Google можно парсить метаданные, заголовки, наименования товаров, цены, почту и многое другое.
Рассмотрим самые популярные и полезные функции и их применение.
Функция importHTML
Настраивает импорт таблиц и списков на страницах сайта. Прописывается следующим образом:
Пример использования
Нужно выгрузить табличные данные со страницы сайта.
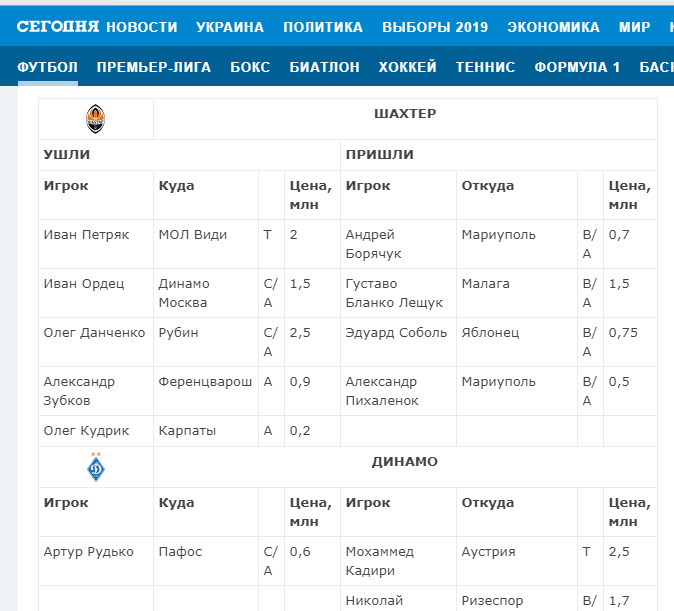
Для этого в формулу помещаем URL страницы, добавляем тег «table» и порядковый номер — 1.
Вот что получается:
Вставляем формулу в таблицу и смотрим результат:
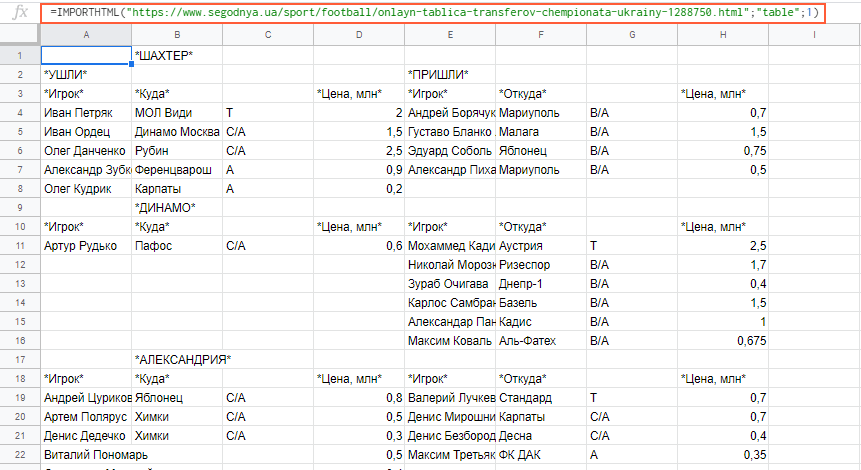
Функция importXML
Импортирует данные из документов в форматах HTML, XML, CSV, CSV, TSV, RSS, ATOM XML.
Функция имеет более широкий спектр опций, чем предыдущая. С её помощью со страниц и документов можно собирать информацию практически любого вида.
Работа с этой функцией предусматривает использование языка запросов XPath.
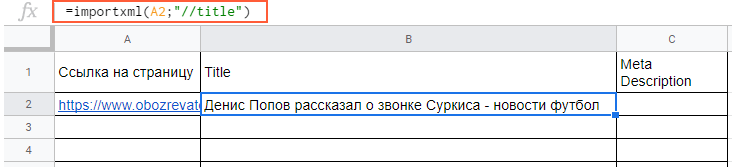
Пример использования
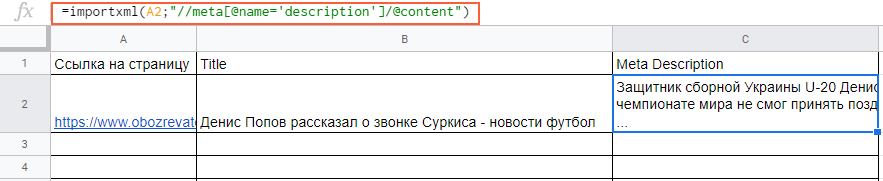
Вытягиваем title и meta description. В первом случае в формуле просто прописываем слово title:
В формулу можно также добавлять названия ячеек, в которых содержатся нужные данные.
С парсингом description нужно немного больше заморочиться, а именно прописать его XPath. Он будет выглядеть так:
В случае с другими любыми данными XPath можно скопировать прямо из кода страницы.
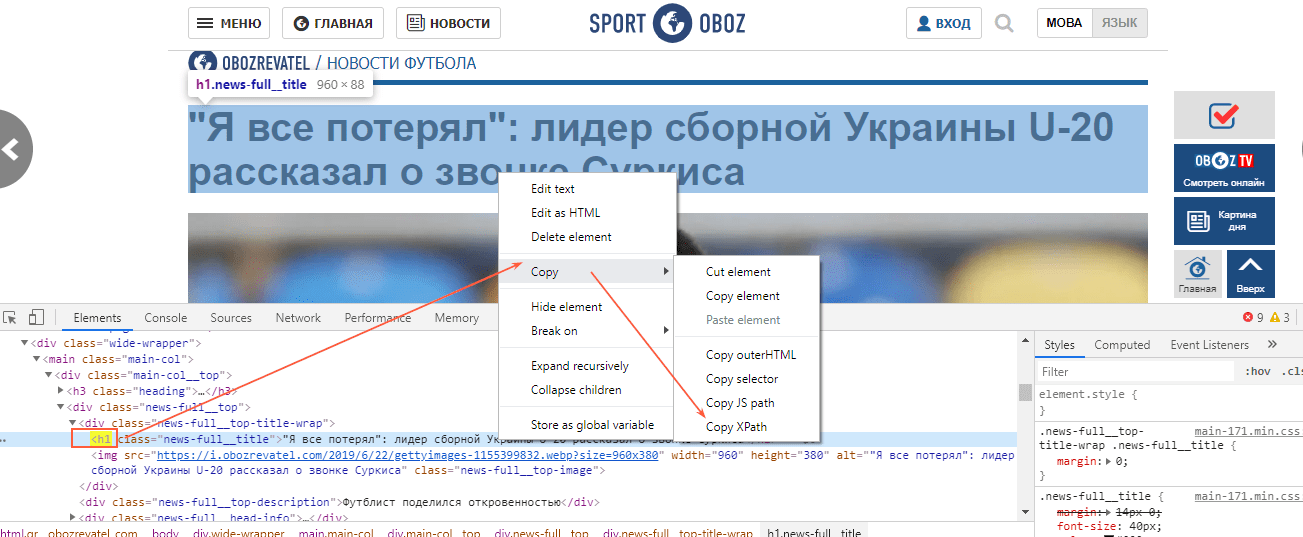
Вставляем в формулу и получаем содержимое meta description.
Функция REGEXEXTRACT
С её помощью можно извлекать любую часть текста, которая соответствует регулярному выражению.
Пример использования
Нужно отделить домены от страниц. Это можно сделать с помощью выражения:

Подробнее об этой и других функциях таблиц вы можете почитать в справке Google.
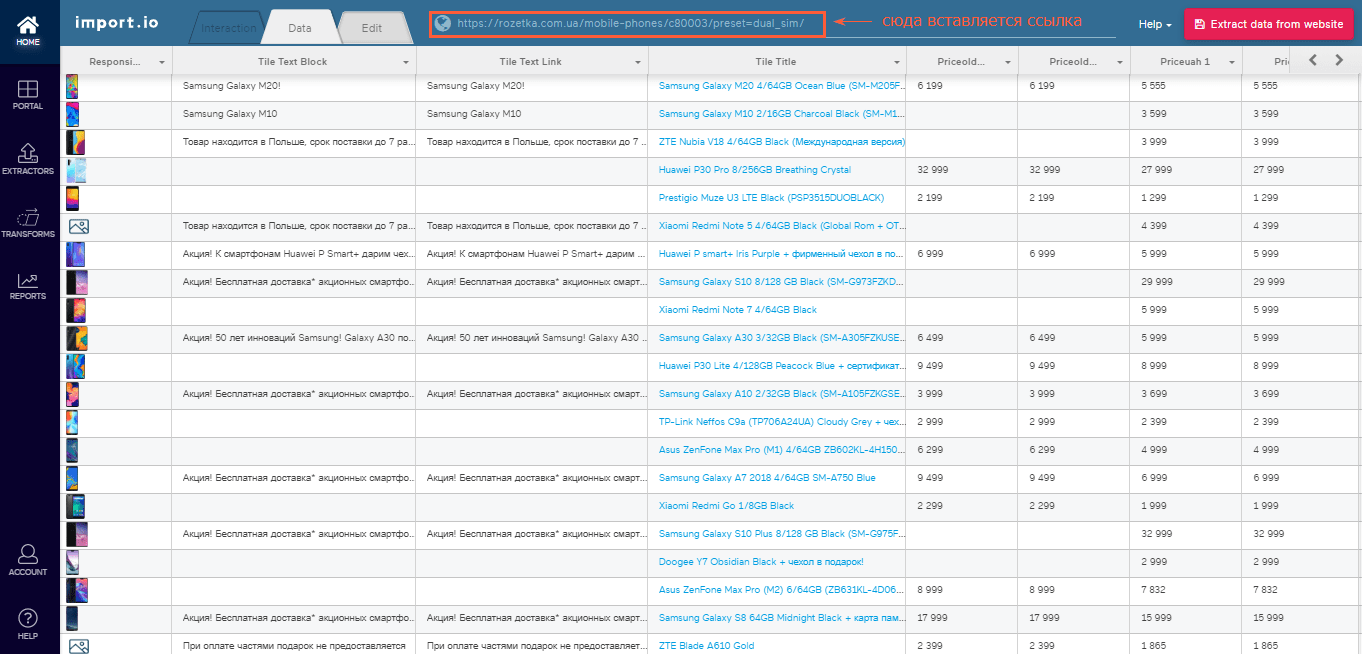
Эта онлайн-платформа позволяет парсить и формировать данные с веб-страниц, а также экспортировать результаты в форматах Excel, CSV, NDJSON. Для использования import.io не требуется знания языков программирования и написания кода.
Чтобы начать парсить, необходимо вставить ссылку страницы, из которой вы хотите тянуть данные, и нажать на кнопку «Extract data».
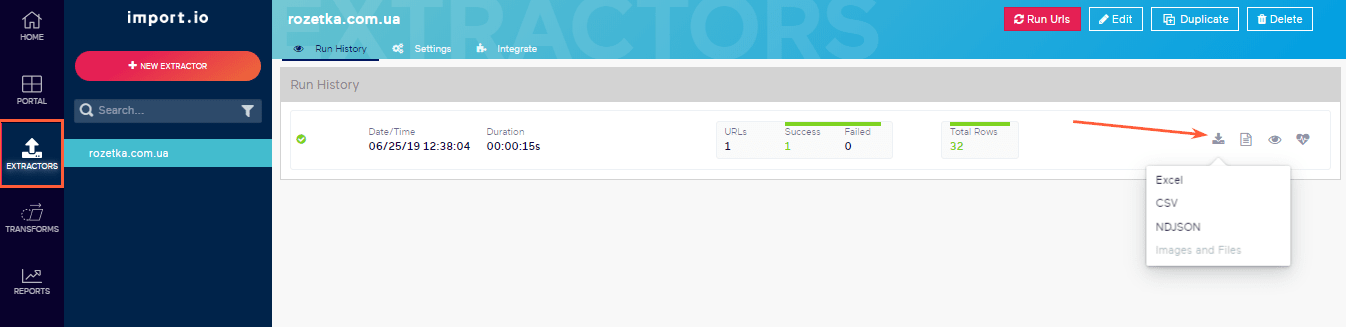
Для экспорта отчётов нажмите на иконку сохранения, затем перейдите в раздел «Extractors» и нажмите на кнопку скачивания.
Netpeak Spider
Netpeak Spider проводит SEO-аудит и позволяет проводить кастомный парсинг данных с сайтов.
Функция парсинга позволяет настраивать до 15 условий поиска, которые будут выполняться одновременно.
Чтобы извлечь данные со страниц сайта, выполните такие действия:
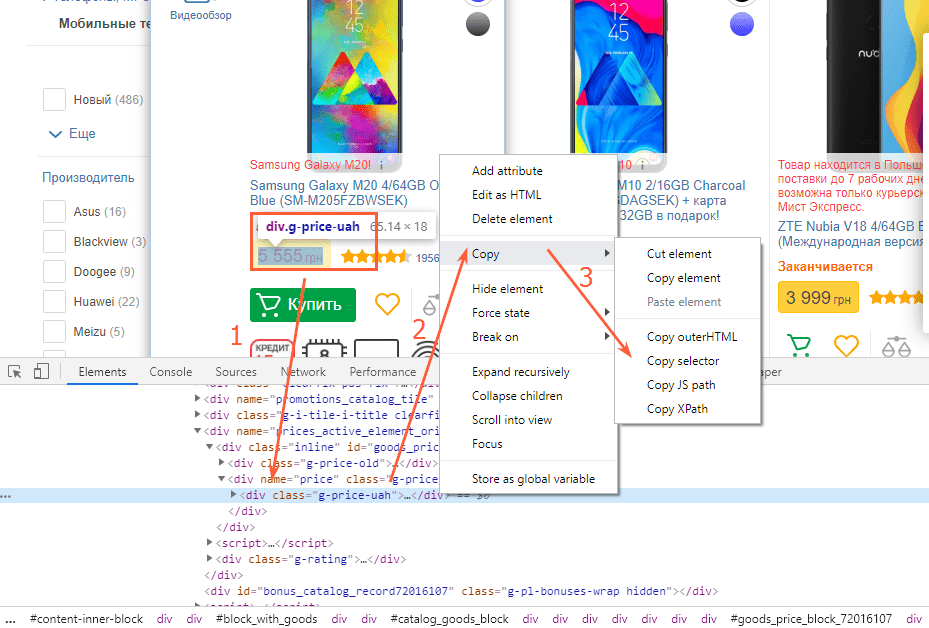
- Откройте страницу, с которой хотите собрать данные.
- Скопируйте XPath или CSS-селектор нужного элемента (например, цены).
- Откройте программу, перейдите в меню настроек «Парсинг» и включите функцию (поставить «галочку»).
- Выберите нужный режим поиска и область «Внутренний текст».
- Вставьте XPath или CSS-селектор, который вы ранее скопировали.
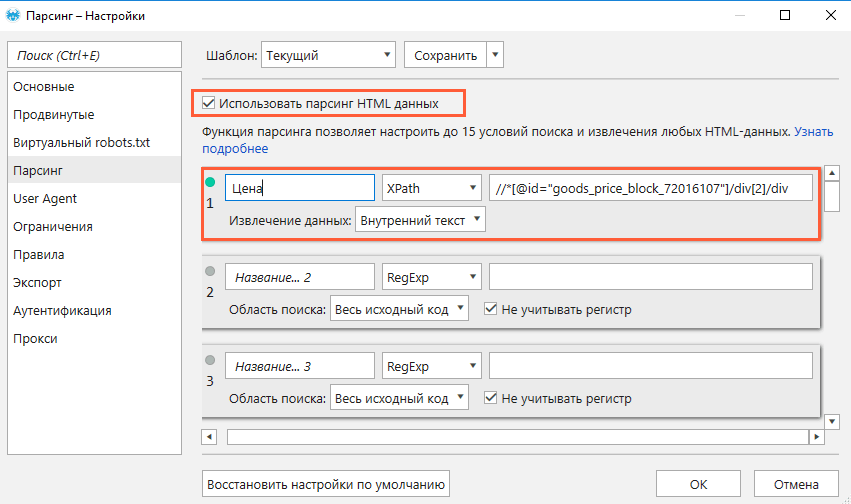
- Сохраните настройки.
- Вставьте домен сайта в адресную строку или загрузите список нужных страниц (через меню «Список URL» или горячими клавишами Ctrl+V, если список сохранён в буфер обмена).
- Нажмите «Старт».

- По завершении анализа перейдите на боковую панель, откройте вкладку «Отчёты» → «Парсинг» и ознакомьтесь с результатами.
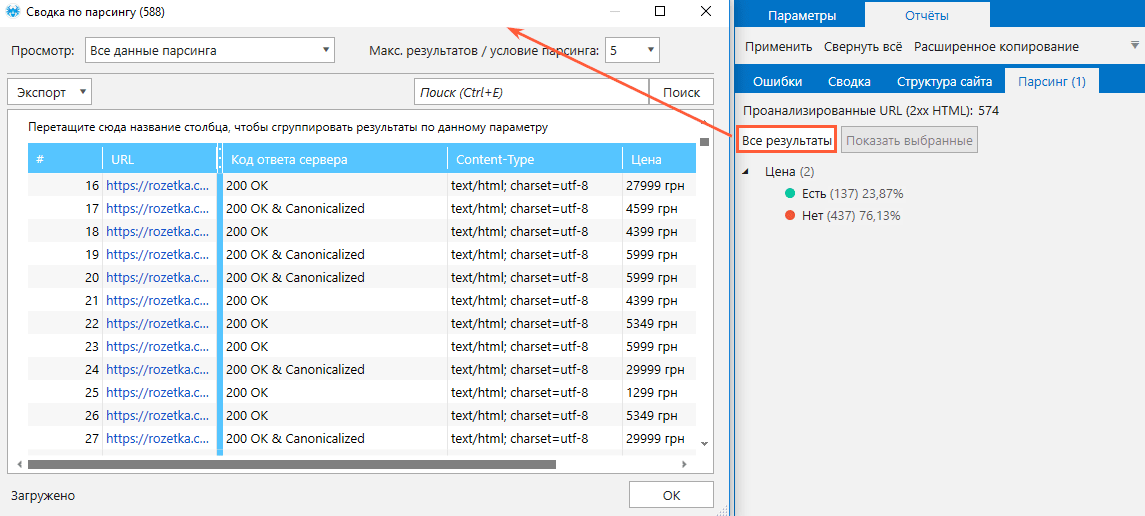
При необходимости выгрузите данные в формате Excel или CSV с помощью кнопки «Экспорт».
Netpeak Checker
Это десктопный инструмент, который предназначен для массового анализа доменов и URL и частично повторяет функционал Netpeak Spider (сканирует On-Page параметры страниц).
Netpeak Checker позволяет за считаные минуты спарсить выдачу поисковых систем Google, Яндекс, Bing и Yahoo.
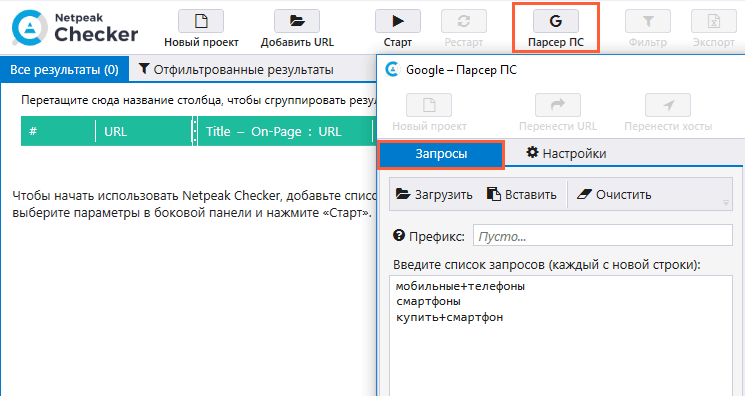
Чтобы запустить парсинг, проделайте следующее:
- Из основного окна программы перейдите в окно инструмента «Парсер ПС».
- Пропишите запросы, по которым будет парситься выдача. Если в запросе несколько слов, каждое слово должно отделяться знаком «+» без пробела.
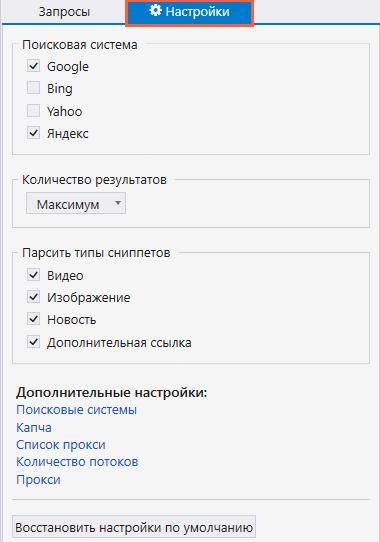
- Перейдите на соседнюю вкладку «Настройки», где вы можете выбрать поисковые системы, выставить нужное количество результатов и выбрать тип сниппета.
- Нажмите на «Старт», чтобы запустить парсинг.
- По завершении ознакомьтесь с полученными результатами в таблице.

Приложение ParseHub позволяет парсить сайты и обрабатывать JavaScript, AJAX, файлы cookie и работать с одностраничными приложениями.
Процедура извлечения данных со страниц или сайта строится таким образом:
- Создайте новый проект и введите адрес сайта или страницы, с которой вы хотите спарсить данные.
- После того как загрузка закончилась, начинайте выбирать нужные элементы (все элементы, которые вы выберете, отобразятся слева).

- После того как вы выбрали все нужные элементы, нажмите на кнопку «Get Data».
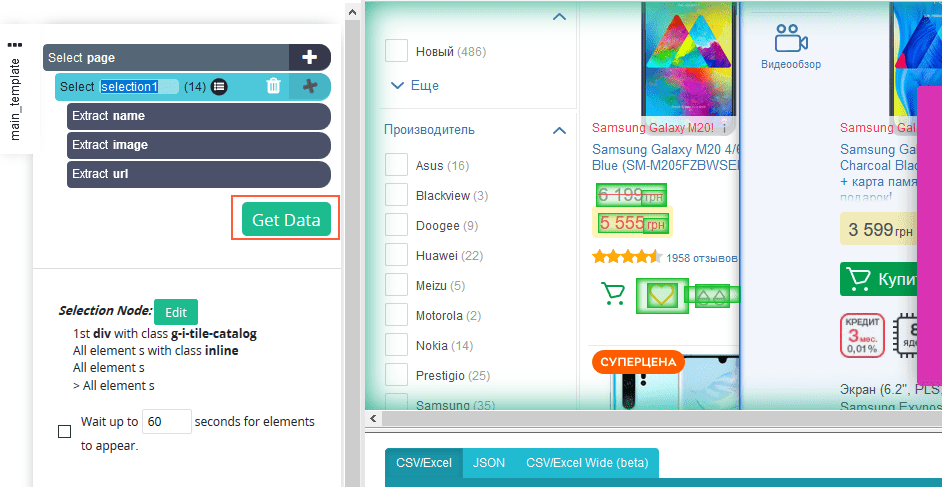
- Затем нажмите «Run».
- После завершения анализа скачайте полученные данные в удобном для вас формате.
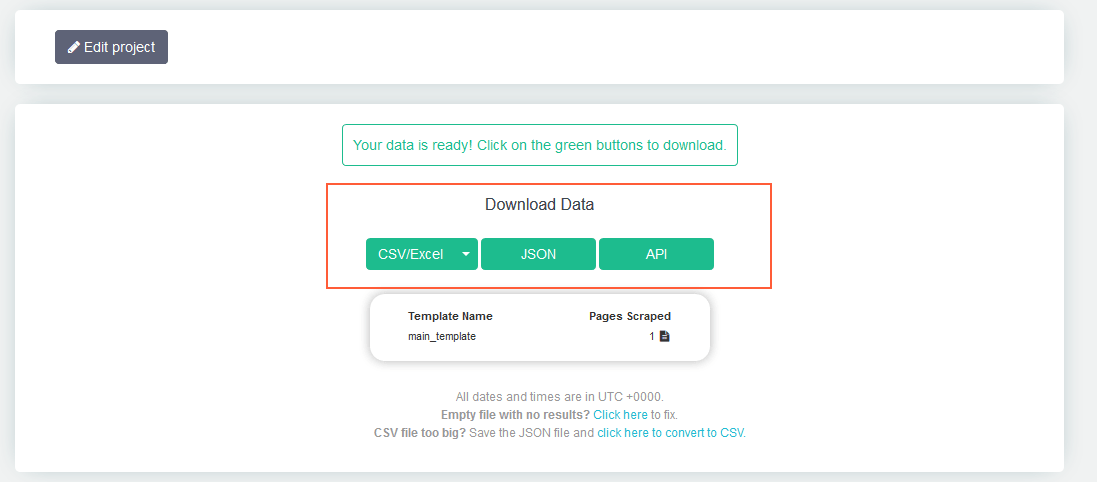
4. Законно ли парсить чужие сайты
Парсинг данных с чужих сайтов не является нарушением закона, если при этом:
- извлекаемая информация размещена в открытом доступе и не составляет коммерческую тайну;
- не нарушаются авторские права и условия обслуживания;
- автоматизированный парсинг осуществляется законным доступом;
- парсинг не нарушает работу сайта.
Если вы не совсем уверены в своих действиях и опасаетесь, что можете преступить закон, перед парсингом лучше проконсультироваться с юристом.
Подводим итоги
Сбор и систематизация веб-данных — это трудозатратный процесс, который может отнимать несколько (даже десятков) часов. Но стоит его автоматизировать, и дело идёт на лад: времязатраты значительно сокращаются, а извлечение информации становится более эффективным. Для автоматизации есть немало программ и сервисов, которые отлично справляются с ролью парсера: можно тестировать и выбирать на свой вкус.
Но помните, что прежде чем собирать и заимствовать какие-либо данные с чужих сайтов, необходимо убедиться, не является ли это нарушением закона.
Поделитесь своими методами автоматизации парсинга в комментариях и расскажите, возникали ли у вас какие-либо проблемы при этом?
Как выгрузить товары в Excel?
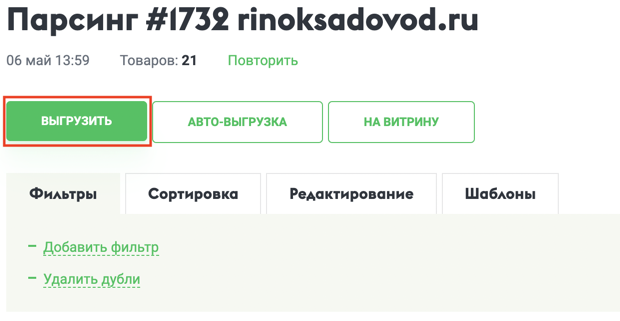
1. В списке товаров нажмите «Выгрузить»
После загрузки товаров на парсер, находясь на странице со списком товаров, нажмите кнопку «Выгрузить».
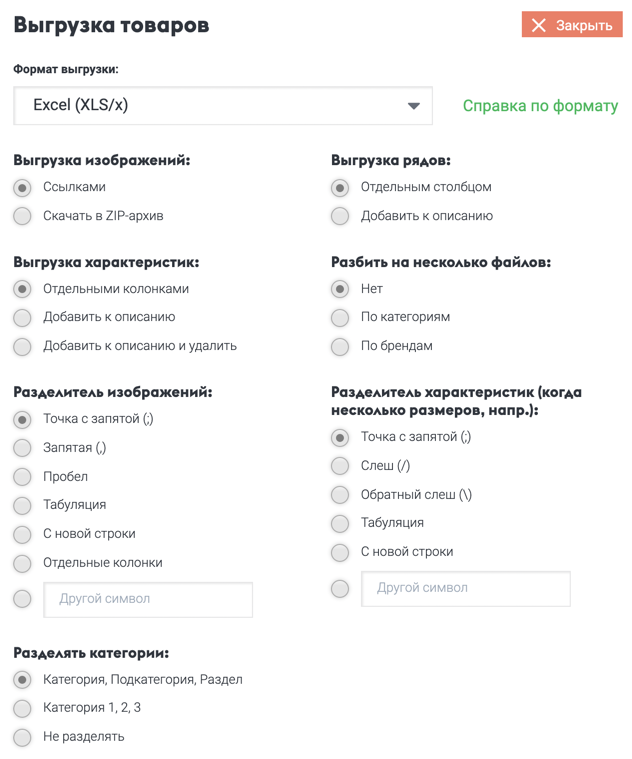
2. Задайте настройки файла
В появившемся окне выберите формат «Excel (XLS/x)» и задайте настройки формата: версия Excel (XLS или XLSx), разделение характеристик и пр..
Обратите внимание, что формат Excel5 не поддерживает больше 65535 товаров в одном файле.
Подробное описание каждой настройки вы можете найти ниже на этой странице.
3. Выгрузка запущена
Появится индикатор выгрузки товаров. Если не хотите ждать, вы можете выключить компьютер или закрыть браузер — выгрузка продолжится независимо от вас.
По окончанию выгрузки вы увидите ссылку на скачивание файла Excel. Если будет сформировано несколько файлов, появится список ссылок.

Встраивание изображений в ячейки
Для формата Excel имеется возможность автоматического встраивания изображений в ячейки таблицы. Для этого необходимо выбрать соответствующую опцию в разделе «Выгрузка изображений» окна выгрузки.
В ячейку всегда выгружается первое изображение уменьшенного размера.
Настройки формата:
Разделитель изображений — символ для разделения нескольких ссылок изображений внутри одной колонки. Можно задать разбиение нескольких картинок по отдельным колонкам.
Разделитель характеристик — символ для разделения нескольких характеристика товара внутри одной колонки. Например, цветов: красный/синий/зеленый.
Формат файла — позволяет указать формат файла версии Excel. Обратиет внимание, что формат Excel5(XLS) не поддерживает более 65535 строк (товаров).
Общие настройки:
Выгружать товары — позволяет выбрать какие товары выгружать по признаку «Наличие» на сайте поставщика.
Порядок выгрузки товаров — позволяет выбрать порядок выгрузки товаров и установить выгрузку задом наперед при желании.
Разрешить HTML разметку в полях товара — разрешает или запрещает HTML-разметку в полях товара. Очень редко используется интернет-магазинами.
Выгрузка изображений — позволяет изменить число или способ выгрузки изображений.
Имеется возможность скачать все изображения товаров в виде архива. Для этого выберите опцию «Поместить в ZIP-архив» при выгрузке.
Выгрузка характеристик — позволяет выгрузить свойства товаров (цвета, размеры и пр.) отдельными полями в файле или просто добавить к общему описанию товара. При добавлении к описанию сами колонки остаются. Выбирается в зависимости от возможностей вашего интернет-магазина или сайта СП.
Выгрузка рядов — аналогично выгрузке характеристик, но в отношении рядов товара. Позволяет добавить инфомрацию о рядах к описанию.
Разделять категории — разделять вложенные категории на разные поля (по цифрам или по названиям).
Разбить на несколько файлов — позволяет разбить выгрузку на несколько файлов: по категориям или по брендам.
Сохранение результатов в формате Excel (.xlsx)
Описание способа сохранения данных в XLSX
- В техническую поддержку довольно часто поступают вопросы о возможности сохранять результаты парсинга сразу в виде xlsx файлов (стандартный формат Excel). Обычно мы рекомендуем использовать CSV, т.к. это по сути текстовый формат и выводить в таком виде результаты можно без каких-либо дополнений.
Но, благодаря возможности подключать Node.js модули, стало возможным сохранение в XLSX. Стоит сразу отметить, что это требует некоторых дополнительных манипуляций, но в целом в этом нет ничего сложного. И в этой статье будет показан реальный пример парсинга с сохранением в Excel.
 В техническую поддержку довольно часто поступают вопросы о возможности сохранять результаты парсинга сразу в виде xlsx файлов (стандартный формат Excel). Обычно мы рекомендуем использовать CSV, т.к. это по сути текстовый формат и выводить в таком виде результаты можно без каких-либо дополнений.
В техническую поддержку довольно часто поступают вопросы о возможности сохранять результаты парсинга сразу в виде xlsx файлов (стандартный формат Excel). Обычно мы рекомендуем использовать CSV, т.к. это по сути текстовый формат и выводить в таком виде результаты можно без каких-либо дополнений. Рассмотрим такую задачу:
Как видно из примера выше, в каждой строке (кроме первой) есть переменная sheet — это название листа, и data — это строка данных в виде массива, где каждый элемент — это отдельная ячейка.
Настроив сохранение в таком виде, можно переходить ко 2-му этапу.
Для создания xlsx файла воспользуемся модулем Node XLSX. По ссылке можно посмотреть примеры использования и ознакомиться с возможностями.
Устанавливаем данный модуль и приступаем к написанию небольшого JS-парсера, который должен будет сконвертировать полученные на 1-м этапе данные в нужный нам формат. В качестве запросов будет указываться файл результатов из 1-го этапа.
Т.к. этот модуль (и в целом формат XLSX) не позволяют добавлять данные в уже существующий файл, а многопоточные чтение-добавление-запись сильно замедлят работу (либо даже могут привести к ошибкам), то воспользуемся пакетным чтением списка запросов и считаем все запросы из файла за один раз. Для этого укажем в defaultConf переменную bulkQueries и зададим большое значение, например 1000000 (чтобы гарантировано считать все данные из файла).
После сортировки мы получаем массив output, в необходимом виде. Остается только сформировать результирующий файл и завершить работу.
Сохраняем получившийся парсер в отдельное задание и возвращаемся к 1-му этапу. Объединяем оба пресета в цепочку заданий , указав запуск второго с файлом результатов от первого. Этим мы автоматизируем конвертацию полученных данных.
Указываем ссылки для парсинга, запускаем и получаем итоговый файл в формате xlsx такого вида: 
Как видно на скриншоте, для каждого производителя создан отдельный лист с данными о товарах, а значит поставленная задача решена полностью.
Аналогичным образом можно формировать более сложные файлы, сохранять больше данных и применять форматирование.